Mécanique de la compilation C++
Ce qu'on nomme compilation, par souci de simplicité, est souvent un abus de langage, du fait que nous tendons à y regrouper la combinaison de plusieurs actions connexes incluant la compilation à proprement dit.
Un projet
Résumé: un programmeur analyste développe un ou plusieurs algorithmes qu'il traduit en programme dans un langage donné. L'objectif du code ainsi produit est d'en faire un exécutable, soit un automatisme permettant de résoudre un problème ou une classe de problèmes.
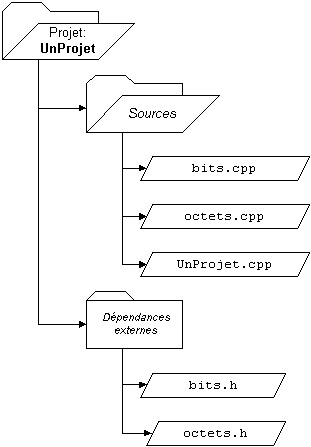
Dans nos exemples plus bas, nous présumerons un projet nommé "UnProjet" qui inclura les fichiers source "octets.cpp", "bits.cpp" et "UnProjet.cpp", et aura pour but de générer l'exécutable "UnProjet.exe".
On pourrait donc dire, à la limite, que le projet du projet "UnProjet" est la génération de l'exécutable "UnProjet.exe".
|
Commençons par quelques définitions:
Puisque la programmation C++ a pour but de générer des exécutables, il est de mise d'y construire des projets. Au minimum, tous les fichiers source utilisés devront y figurer.
Les fichiers essentiels à la génération d'un exécutable sont les suivants:
|
|
Question piège:
|
combien d'exécutables la compilation d'un projet générera-t-il?
|
La compilation C++
Il y a au moins deux manières, grossièrement, de prendre du code source et d'en faire un exécutable: le compiler, et l'interpréter. Ici, nous allons nous intéresser à la mécanique de la compilation, spécialement pour le langage C++.
Le code machine produit par la compilation n'est pas un exécutable, mais y ressemble beaucoup. On dit de ce code que c'est du code objet (".obj").
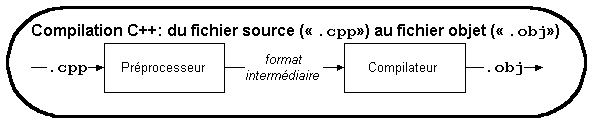
On compile donc du code source (".cpp" pour le langage C++) pour générer du code objet (".obj" sur plate-forme Win32), mais la compilation en soi n'est pas suffisante pour générer un exécutable.
Dans le schéma plus haut, on remarque qu'il y a une phase précédant la compilation en langage C++ (comme en langage C). C'est la phase de précompilation, et nous allons commencer par nous attarder à cette étape.
|
Question piège:
|
peut-on compiler un fichier d'en-tête (".h")?
|
Le préprocesseur
Le préprocesseur est un outil qui modifie le code source avant que le compilateur n'entre en oeuvre. Ses directives débutent toutes par un dièse (#) se trouvant dans la première colonne d'une ligne de code, et ne se terminent pas par un point virgule (;).
Dans cette section, nous porterons notre regard sur les possibilités et les limites de cet outil, en nous concentrant sur ses principales commandes (ou directives).
Directives de définition de symboles
|
Directive
|
Signification et effet
|
|
#define <sym> [<rempl>]
|
Définit le symbole <sym>, associé (de façon optionnelle) au texte de remplacement <rempl>.
Si le symbole est associé à un texte de remplacement, alors chaque occurrence de <sym> dans le code source sera remplacé par <rempl>.
|
|
#undef <sym>
|
Élimine la définition du symbole <sym>. À partir de cet endroit, le symbole en question n'existe plus.
|
La directive #define crée un symbole pour le préprocesseur. Ce symbole peut, de façon optionnelle, avoir une valeur. Le cas où aucun texte de remplacement n'est offert sera couvert plus bas (directives d'inclusion conditionnelle), là où il prendra son sens.
Symboles avec texte de remplacement
Prenons l'exemple suivant:
Ceci associe au symbole "XYZ" l'équivalent lexical "3". Ainsi, à chaque endroit que le préprocesseur rencontrera dans le texte du code source ayant défini cette directive le mot "XYZ", il le remplacera par "3".
|
Avant le préprocesseur
|
Après le préprocesseur
|
#define XYZ 3
|
|
int a = XYZ
|
int a = 3
|
z = f (-XYZ);
|
z = f (-3);
|
#define FRED 33
int somme (int a, int b)
{
return (a + b);
}
int main ()
{
int a= -FRED* 4+ somme (FRED, -4);
} // main ()
|
int somme (int a, int b)
{
return (a + b);
}
int main ()
{
int a= -33* 4+ somme (33, -4);
} // main ()
|
|
Question piège:
|
quelle sera la valeur de z dans ce qui suit?
#define A 4
#define B ((A < b)? A: b)
int main ()
{
int b= 3, z= B;
}
|
Directives d'inclusion de fichier
|
Directive
|
Signification et effet
|
#include <fichier1.h>
|
Sera remplacé par le texte du fichier "fichier1.h" par le préprocesseur, qui le cherchera dans les librairies du système.
|
#include "fichier2.h"
|
Sera remplacé par le texte du fichier "fichier2.h" par le préprocesseur, qui le cherchera d'abord dans le répertoire courant.
|
La directive #include demande au préprocesseur d'inclure le texte d'un fichier à la place de la directive d'inclusion elle-même.
// cette ligne sera remplacée par le texte du fichier math.h
#include <math.h>
// cette ligne sera remplacée par le texte du fichier bits.h
#include "bits.h"
|
La différence entre un fichier inclus entre <> et un autre inclus entre "" est la suivante:
|
Question piège:
|
si "a.cpp" contient la ligne
#include "a.h"
et "b.h" contient la ligne
#include "a.h"
et "c.h" contient les lignes
#include "b.h"
#include "a.h"
et si "c.cpp" contient les lignes
#include "c.h"
combien de fois le texte du fichier "a.h" se retrouvera-t-elle dans "c.cpp"?
|
On inclut un fichier parce que...
En effet, si on prend l'exemple d'une déclaration de type, avoir une seule déclaration qui puisse être inclue par différents fichiers source, inclure ce fichier assure que tous les fichiers source perçoivent exactement le même type.
Exemple: si le fichier "octets.h" contient (entre autres) la déclaration suivante:
typedef enum { partieHaute, partieBasse } partieDOctet;
|
alors tout fichier ayant la directive suivante:
s'assurera d'inclure de facto la déclaration du type "partieDOctet" s'y trouvant. Ceci évite que quelqu'un décide de définir localement le même type, et rédige par exemple (erronément) ce type comme suit:
typedef enum
{
partieBasse, partieHaute
}
partieDOctet;
|
Les valeurs associées aux constantes énumérées "partieBasse" et "partieHaute" dans les deux cas ne sont pas les mêmes, ce qui pourrait conduire à des problèmes de logique lors de l'exécution du programme.

|
Dans le schéma à gauche, les flèches indiquent le sens de l'inclusion des fichiers.
|
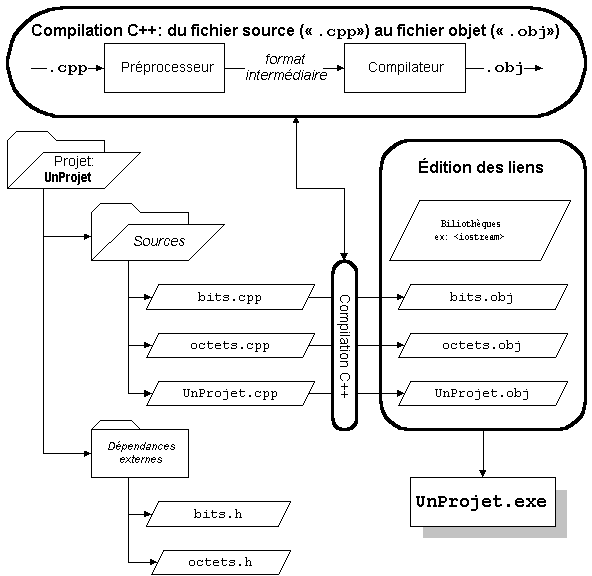
Remarquez que "bits.h" est inclus par "bits.cpp" et par "UnProjet.cpp". Ceci signifie que le texte de "bits.h" fera partie de "bits.cpp" et fera partie de "UnProjet.cpp".
La même règle s'applique ici au contenu de "octets.h", qui se retrouve intégralement dans "octets.cpp" et dans "UnProjet.cpp".
Cela signifie que le type "partieDOctet" (mentionné en exemple plus haut), dans "octets.h", fait partie des fichiers "octets.cpp" et "UnProjet.cpp", mais ne fait pas partie de "bits.cpp".
Que compile-t-on?
On ne compile, en C++, que des fichiers source. Les fichiers d'en-tête servent de support à la compilation, mais ne sont pas compilés.
Ainsi, pour le projet "UnProjet" en exemple ici, les fichiers "bits.cpp", "octets.cpp" et "UnProjet.cpp" seront compilés, mais pas les fichiers "bits.h" et "octets.h". Toutefois, ces derniers seront inclus dans des fichiers source pour que ceux-ci aient tout le nécessaire pour être correctement compilés.
Dans notre exemple, on présumera avoir écrit des fonctions capables de manipuler des bits et des octets (respectivement dans "bits.cpp" et dans "octets.cpp"). Le module "UnProjet.cpp" comptera sur leur existence pour sa propre exécution.
Exemple: le fichier "bits.h" contient le prototype de fonction suivant:
bool Lire_Bit (unsigned short Mot, unsigned char Position);
|
Tout fichier ayant la directive suivante:
s'assurera d'inclure de facto le prototype en question.
Ceci signifie que tous les fichiers source connaissant ce prototype savent comment appeler une fonction appelée "Lire_Bit()", retournant un "bool", et prenant deux paramètres (un "unsigned short" et un "unsigned char").
|
Note:
|
inclure les prototypes des fonctions n'est pas la même chose qu'inclure le corps (la définition) de ces fonctions.
|
Le lien entre la fonction appelée et le code associé, lors de l'appel de code se trouvant dans un autre fichier objet, se fera lors de l'édition des liens.
Prototypes de fonctions
Un prototype de fonction déclare son nom, la description (type et nom) de ses paramètres, et (de façon optionnelle) le type de sa valeur de retour.
|
Question piège:
|
quelles sont les fonctions différentes dans ce qui suit?
int f (int);
int g (int);
int g (int, int);
void g (int, int);
|
Idée
Le langage C++ nécessite qu'on déclare chaque objet avant de s'en servir, peu importe que cet objet soit un type, une constante, une variable, une fonction, et ainsi de suite.
Parfois, une fonction ne peut être définie avant son appel. Parfois aussi on aimerait utiliser une fonction qui est définie dans un autre module. Dans ces cas, le compilateur C++ acceptera que la définition de la fonction en question vienne après son utilisation, dans la mesure où il en connaît déjà le prototype.
Déclarer un prototype permet au compilateur de reconnaître l'existence de la convention d'appel d'une fonction avant que celle-ci ne soit définie. Ainsi, sans savoir exactement ce que la fonction en question exécutera comme instructions, le compilateur peut en générer le schéma d'appel[1].
Quoi?
Examinez le code suivant:
// Additionner_Doubles (a,b)--retourne la somme de "a" et "b"
double Additionner_Doubles (double a, double b)
{
return (a + b);
}
|
On parle ici de définition d'une fonction, du fait qu'on en voit le prototype, mais aussi le corps, soit le code qui sera exécuté lors d'un appel de ladite fonction.
Le prototype lui-même de cette fonction serait:
double Additionner_Doubles (double a, double b);
|
ou encore (au choix):
// on peut se limiter au nombre et aux types des paramètres...
double Additionner_Doubles (double, double);
|
Le prototype d'une fonction offre donc le minimum nécessaire au compilateur pour que celui-ci puisse produire des appels valides à cette fonction sans avoir à connaître son contenu précis.
Où?
Puisque le rôle du prototype d'une fonction est de suppléer à l'absence de sa définition par l'essentiel de sa convention d'appel. Ainsi, un prototype doit absolument se trouver avant le premier appel à la fonction qu'il représente dans le fichier source.
Le prototype devra posséder (cela va de soi) la même structure que l'en-tête de la définition de la fonction, à la différence que la déclaration ne possède pas de corps et puisqu'il s'agit d'une instruction elle doit se terminer par un point virgule (;).
Syntaxe de la déclaration d'un prototype de sous-programme
[type] nomDeFonction ([type1 [nom1], type2 [nom2], ... typeN [nomN]]);
|
|
Question piège:
|
quels sont les prototypes de fonctions valides dans ce qui suit?
int f (int a);
int g (int);
int g (int, int)
void g (int &a, int b)
{
a = b;
};
|
Obligatoires?
La norme la plus récente du langage C++ oblige à l'utilisation de prototypes de fonctions lorsque celles-ci ne sont pas définies au moment de leur appel. Les compilateurs permettent toutefois, par souci de compatibilité avec le code existant, de contourner cette obligation à l'aide d'options de compilation.
Toutefois, les prototypes sont d'une utilité indéniable. En plus de clarifier le code en tant que tel, ils permettent d'éviter des erreurs fortuites dans l'exécution du code généré.
Directives d'inclusion conditionnelle
|
Directive
|
Signification et effet
|
#ifdef <sym>
|
Le code suivant cette directive fera partie de la compilation seulement si <sym> a été défini par #define précédemment.
La section de code qui suit cette directive doit se terminer par un #elif, un #else ou un #endif.
|
#ifndef <sym>
|
Le code suivant cette directive fera partie de la compilation seulement si <sym> n'a pas été défini par #define précédemment.
La section de code qui suit cette directive doit se terminer par un #elif, un #else ou un #endif.
|
#if <condition>
|
Le code suivant cette directive fera partie de la compilation seulement si <condition> est vrai.
On peut inclure dans <condition> des opérateurs logiques, arithmétiques ou relationnels sur les symboles et leur texte de remplacement, de même que defined <sym> qui est vrai seulement si <sym> a été précédemment défini par #define.
La section de code qui suit cette directive doit se terminer par un #elif, un #else ou un #endif.
|
#elif <condition>
|
Équivalent d'un "else if" pour le préprocesseur. Les règles du #if s'appliquent.
|
#else
|
Équivalent d'un "else" pour le préprocesseur.
La section qui suit un #else fera partie de la compilation dans la mesure où aucune des directives #if, #ifdef, #ifndef ou #elif la précédant logiquement n'ont été évaluées comme vraies.
Doit se terminer par un #endif.
|
#endif
|
Termine la section d'une directive #if, #ifdef, #ifndef, #elif ou #else.
|
|
Note:
|
l'annexe 1 de ce document explique comment éviter les problèmes d'inclusion multiple d'un fichier d'en-tête à l'aide de symboles et du mécanisme d'inclusion conditionnelle. Nous vous invitons fortement à vous familiariser avec cette mécanique...
|
|
Question piège:
|
laquelle des versions de "fonctionBizarre()" sera celle appelée dans la procédure "main()"?
#define ROGER
#define BIQUETTE 4
#ifndef ROGER
int fonctionBizarre (int z)
{
return (z * 34 - (z*z)/15);
}
#elif defined BIQUETTE && (BIQUETTE >= 3)
int fonctionBizarre (int z)
{
return ((float)z / 15 - (1.0/z));
}
#else
int fonctionBizarre (int z)
{
return (-1);
}
#endif
int main ()
{
int a= fonctionBizarre (4);
} // main()
|
Directives indigènes
Bien que le langage C++ permette d'écrire des programmes qui soient "portables", un anglicisme au sens d'être utilisable sur plusieurs plates-formes, il est possible d'utiliser des directives indigènes (en anglais, "native") à chaque plate-forme.
Cette tactique devrait être tenue au minimum, puisqu'elle limite les possibilités d'un programme aux plates-formes où une directive indigène donnée existe.
Nous ne couvrirons pas l'étendue des directives indigènes dans ce document--ce ne serait pas pertinent. Si vous avez envie d'en savoir plus, consultez la documentation de votre outil de travail.
|
Directive
|
Signification et effet
|
#pragma <varia>
|
La directive #pragma permet des effets dépendants de la plate-forme de développement. Ses effets et possibilités changent selon le compilateur utilisé.
|
Le compilateur
Une fois que le préprocesseur aura terminé son travail, le compilateur cherchera à traduire le code source en code objet.
Pour ce faire, il accomplira trois types de validation:
Dans les trois cas, il produira des erreurs s'il n'est pas en mesure de générer du code objet étant donné le code source qu'on lui demande de traduire, et produira des avertissements s'il note des instructions à première vue douteuses mais ayant un certain risque de fonctionner.
|
Note:
|
une fois rendu à la compilation à proprement dit, il n'y a plus qu'un fichier source à traduire en code objet. Les fichiers d'en-tête inclus en chemin se sont fondus dans le code source en traitement.
|
Ce qui manque au code objet pour en faire un exécutable
Le code objet contient le fruit de la compilation, mais n'est pas tout à fait au point. Il lui manque plusieurs petites choses pour pouvoir être transformé en exécutable. La première chose qui lui manque, d'ailleurs, est le code requis pour exécuter correctement les fonctions définies dans d'autres modules.
Par exemple, si "UnProjet.cpp" contient un appel à la fonction "Lire_Bit()" définie dans "bits.cpp", la compilation de "UnProjet.cpp" en "UnProjet.obj" aura été rendue possible du fait que le prototype de la fonction se trouve dans "bits.h", que "UnProjet.cpp" incluait (sagement).
Par contre, du fait que le prototype d'une fonction se résume à sa convention d'appel, pas à son corps, il faut à un moment donné que le code (compilé dans "bits.obj", puisque la définition se trouvait dans "bits.cpp") de cette fonction soit liée au code objet se trouvant dans "UnProjet.obj".
L'éditeur de liens (linker)
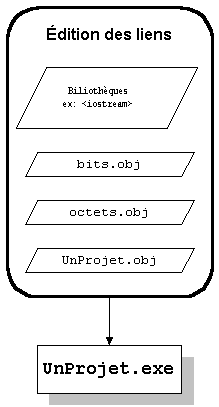
|
Un programme spécial se charge généralement des "résolutions externes" requises pour passer du code objet à du code exécutable.
L'éditeur de liens cherchera à résoudre les liens externes à chaque module objet (".obj"), dans le but d'en arriver à un exécutable cohérent.
Ainsi, il pourra rencontrer certaines situations l'empêchant de réaliser sa tâche, la plupart du temps parce qu'il sera incapable de faire un choix entre plusieurs entités équivalentes.
Quelques exemples classiques:
|
|
Note:
|
ci-après se trouve un schéma global du processus de compilation, tel que nous l'avons vu jusqu'ici.
|
[1] Nous reviendrons sous peu sur le schéma du fonctionnement d'appels de sous programmes.