|
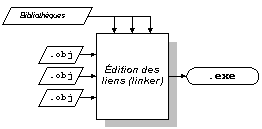
Un module objet est composé de code machine auquel il manque un "dernier effort" pour être exécuté (l'édition des liens, qui sera le sujet d'un cours très bientôt). L'exécutable est composé de code machine, et est prêt à être utilisé. |
|
|
Un module objet est composé de code machine auquel il manque un "dernier effort" pour être exécuté (l'édition des liens, qui sera le sujet d'un cours très bientôt). L'exécutable est composé de code machine, et est prêt à être utilisé. |
|
En toute honnêteté, on programme de moins en moins directement en langage d'assemblage, sauf dans quelques cas bien précis où la tâche est relativement simple et où on est sous de fortes contraintes de performance.
Toutefois, il serait bien mal venu pour un(e) informaticien(ne) de ne pas connaître (et comprendre) les concepts derrière ces langages.
|
Langage machine |
Langage d'assemblage |
|---|---|
|
Le langage machine (ou code machine) est le seul langage que le processeur d'une machine donnée comprenne réellement. On parle de code machine lorsqu'on veut discuter des instructions propres au processeur, et représentées de façon numérique. Chaque instruction que le processeur puisse comprendre se représente par un nombre. Toutes les instructions du langage machine prennent un nombre fixe de paramètres, entre 0 et 2 (ou 3, selon les processeurs) inclusivement. |
Le code machine étant une série de nombres (instruction, [[paramètre0], paramètre1], etc.), sa lecture et sa programmation par des humains sont très fastidieuses. C'est pourquoi un utilise un équivalent "lisible" nommé langage d'assemblage. On transforme un programme écrit en langage d'assemblage en code objet avec un outil nommé assembleur. À chaque mnémonique (instruction au nom simple) du langage d'assemblage pour un processeur correspond une instruction machine; de même, les paramètres des instructions en langage d'assemblage rejoignent ceux de leurs équivalents en langage machine. |
Lorsqu'on exécute un programme, il faut évidemment que celui-ci ait été traduit en code machine exécutable pour la plate-forme sur laquelle il sera exécuté. Mais une fois cette traduction faite, qu'est-ce qui fait qu'en bout de ligne, un programme s'exécutera?
|
Note: |
certains des termes introduits ici seront explicités plus loin; patience! |
Pour qu'un programme s'exécute, il faut d'abord qu'il soit chargé en mémoire. C'est une maxime fort importante, mais qui devient une règle lorsqu'on regarde de plus près la mécanique de son exécution.
Évidemment, charger un programme en mémoire est une chose, mais choisir où il sera placé dans ce large espace qu'on nomme mémoire vive est une tâche en soi. En effet, un programme a une certaine taille, et la mémoire vive peut être vue comme un espace de rangement où une bonne partie de l'espace disponible est déjà occupé.
Qu'est-ce qui définit l'espace requis par un programme prêt à s'exécuter? On pourrait offrir une réponse simplifiée mais adéquate en mentionnant les composantes suivantes[2]:
On peut donc subdiviser l'espace occupé par un programme en mémoire de la façon suivante: un segment de données ("data segment"), un segment de pile ("stack segment") et un segment de code ("code segment"). Et chacun de ces segments est, pour le programme lui-même, à un endroit précis: une adresse qui lui est propre.
Une fois le programme chargé en mémoire, un registre spécial nommé le pointeur d'instruction (IP, plus bas) reçoit l'adresse de la première instruction à effectuer, puis le processeur entre en scène.
Le travail accompli par le processeur devient, en gros, ceci:
Effectuer l'instruction indiquée par IP IP <-- adresse de la prochaine instruction |
Pour poursuivre notre analyse, il faudra donc s'interroger sur ce qu'est une instruction pour le processeur (donc une instruction en langage machine), ce qu'est en fait IP (un registre, pour être honnête, alors nous allons regarder ce que sont les registres), mais nous allons d'abord poser un regard sur ce qu'est une adresse en mémoire.
De quoi a l'air la mémoire vive? Matériellement, c'est une petite composante électronique qui ressemble à une barre de chocolat CaramilkMD, mais cela est de bien peu d'utilité lorsqu'on discute de la mécanique d'exécution d'un programme.
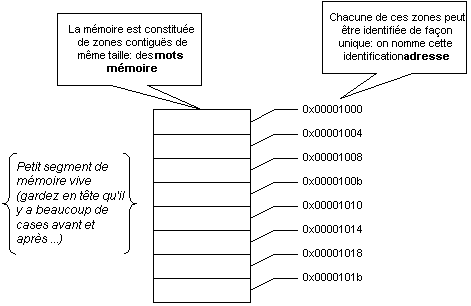
La mémoire vive en tant que telle est (mis à part quelques petites zones bien précises) un espace "tout usage". C'est le compilateur qui décide, à partir d'un programme donné, de définir des segments dédiés à certaines tâches, et c'est le chargeur qui positionne ces segments à des endroits précis en mémoire.
Chaque objet, chaque variable, chaque instruction en mémoire étant quelque part, on peut donc dire de toute chose en mémoire qu'elle a une adresse.
Le concept d'adresse est fort important. On trouve des outils pour manipuler des adresses dans la plupart des langages de programmation, y compris C++. Cela fera d'ailleurs l'objet d'une partie du cours 420 231 que vous allez sans doute adorer.
En pratique, il est utile de noter immédiatement que la taille d'une adresse correspond à celle du mot mémoire[3] (32 bits pour vos stations de travail), et qu'au niveau du code machine, les adresses apparaissent comme de simples entiers non signés sur 32 bits.
Dans le schéma plus haut, remarquez que les adresses offertes sont toutes des multiples de 4 (pour 4 octets <==> 32 bits).
Pourtant, il est parfois pratique de programmer en utilisant des objets de plus petite taille (des entiers sur 16 bits, par exemple, ou même sur huit bits), ou de plus grande taille (des "struct", des classes, des nombres flottants à double précision...). Comment ces deux réalités peuvent-elles être conciliées?
Voici: le processeur a des registres prêts à opérer sur des mots mémoire. Par contre, le langage machine offrant des instructions bit à bit, il lui est possible de contourner les restrictions propres à la taille du mot mémoire par les manipulations appropriées[4].
Aussi, certains langages machine (celui des processeurs Intel inclus) offrent des instructions capables de manipuler des objets de taille différente que celle du mot mémoire, de façon à accélérer le traitement de celles-ci sans devoir passer par des manipulations astucieuses.
En tant que tel, chaque octet en mémoire peut être adressé individuellement; par contre, les opérations les plus rapides en mémoire ont tendance à être celles effectuées sur des objets dont la position en mémoire est un multiple[5] de la taille du mot mémoire.
|
Note: |
les instructions suivantes sont offertes dans le but de vous donner un aperçu du type d'instructions à la disposition du processeur, et donc générées par le compilateur avec votre code source. Remarquez que le ";" joue en assembleur Intel le rôle du "//" en C++. |
C'est avec un langage (vous le verrez) fort restreint que le compilateur passe de vos concepts évolués en C++ à un code objet qui, une fois résolu, deviendra exécutable.
Ces instructions, offertes en exemple, forment un sous-ensemble de l'ensemble constituant le code machine d'un processeur Intel. Présenter ici l'ensemble des instructions de l'assembleur Intel serait lourd et inutile. Le langage d'assemblage varie selon les processeurs, mais les principes sont généralement les mêmes de l'un à l'autre.
|
Instruction |
Opération effectuée |
|---|---|
MOV dest,src |
"Move": dépose le contenu de "src" dans "dest". Le résultat se trouve dans "dest". |
CMP dest,src |
"Compare" les valeurs de "dest" et de "src". Si le résultat est zéro (0), les deux objets ont la même valeur. |
JZ label |
Saute à l'étiquette[6] "label" si le résultat de la dernière comparaison effectuée était zéro (0). Il y a une pléthore de sauts (Jumps) du même acabit, et la mnémonique de chacun commence par un "J". L'instruction "JMP label" est un saut inconditionnel vers l'étiquette "label", alors que tous les autres sauts sont en fait des branchements conditionnels en fonction du résultat de l'opération de calcul la plus récente. |
XOR dest,src |
Fait un "ou exclusif" entre "dest" et "src". Le résultat se trouve dans "dest". On a aussi "AND", "OR" et "NOT" (ce dernier prenant un seul paramètre). |
SHL dest,n |
Glisse vers la gauche ("Shift Left") les bits de "dest" de "n" positions. Le résultat se trouve dans "dest". Il existe aussi "SHR" ("Shift Right") pour un glissement vers la droite. |
ADD dest,src |
Additionne "dest" et "src", et dépose le résultat dans "dest". On trouve aussi "SUB" (pour une soustraction), "MUL", "IMUL", "DIV" et "IDIV" (pour les multiplications et les divisions "normales" ou entières), "INC" et "DEC" (incrémenter et décrémenter), etc. |
LODS STOS |
Ces opérations (sans opérandes) servent à charger un contenu mémoire précis dans un registre[7], et inversement. On verra aussi à l'occasion des instructions "MOV" utilisant des particularités d'adressage de l'assembleur à la place de ces deux instructions. |
|
Note: |
les exemples de code ci-après sont abusifs du côté des constantes. En effet, en assembleur 32 bits, la valeur "0Ah" (par exemple) signifie "10" sur le mode décimal, mais encodé sur 32 bits. Nous tricherons par souci de simplicité. |
Il existe de petits espaces très importants dans le processeur qui servent à entreposer des valeurs utilisées pour fins de traitement efficace (des espèces de "variables matérielles" si on veut). On nomme ces espaces registres, et c'est sur des registres que travaille le mieux le processeur.
En pratique, pour généraliser, on peut voir le traitement de code assembleur sous la forme de la séquence suivante:
C'est un peu simplet, mais l'idée est là. Les plus "actifs" d'entre eux sont les registres dits "tout usage", mais nous faisons ici un petit écart de conduite pour vous donner au moins un début de description pour ce qui est des autres...
Il y a un nombre bien précis de registres dans votre processeur. Certains sont disponibles pour vos propres calculs, et d'autres ont un rôle bien précis à jouer.
Le code objet généré par les compilateurs cherche à tirer profit d'une sage utilisation de ces outils précieux, mais attention: ce n'est pas une mince tâche!
L'accumulateur se nomme AX (16 bits), EAX (32 bits), AH ou AL (8 bits chacun, correspondant respectivement aux parties haute et basse de AX). Il sert à la plupart des opérations arithmétiques courantes, particulièrement celles générées par un compilateur lorsqu'il traduit votre code.
; addition de 10 à la variable X, passant par AX MOV AX,[X] ADD AX,0Ah ; 0Ah en assembleur <==> 0x0a en C++ MOV [X],AX |
Le registre surtout utilisé pour fins d'adressage indexé se nomme BX (16 bits), EBX (32 bits), BH ou BL (8 bits chacun, correspondant respectivement aux parties haute et basse de BX).
Le registre surtout utilisé pour fins de compteur dans des boucles se nomme CX (16 bits), ECX (32 bits), CH ou CL (8 bits chacun, correspondant respectivement aux parties haute et basse de CX).
Exemple:
; initialisation de AX à 0 et de CX à 30...
MOV AX,0
MOV CX,30 ; CX servira de compteur de boucle...
BOUCLE: ADD AX,10 ; BOUCLE est une étiquette
; décrémente CX,et revient à BOUCLE si CX diffère de zéro
LOOP BOUCLE
; suite du programme... AX vaut maintenant 300
|
Le registre surtout utilisé pour fins de support aux multiplications et aux divisions pour un diviseur ou un multiplicateur de plus de huit bits, si les entiers en jeu sont non signés, se nomme DX (16 bits), EDX (32 bits), DH ou DL (8 bits chacun, correspondant respectivement aux parties haute et basse de DX).
Hormis cet usage un peu spécifique, DX peut servir à fins générales (et y est fort utile).
Tel que mentionné plus haut, il existe un certain nombre de segments qui, pris ensembles, constituent le programme lorsque chargé en mémoire. À chacun de ces segments correspond un registre qui, pour le processus en exécution, donne l'adresse à laquelle débute l'espace qui lui a été accordé.
Un registre (qui apparaît comme plusieurs registres au niveau du langage d'assemblage, mais est en réalité un espace subdivisé en plusieurs bits) a pour utilité de signaler les événements pertinents propres aux calculs récents. Il est essentiel au bon fonctionnement de l'arithmétique accomplie par le processeur. Parmi les indicateurs disponibles, on note:
Un certain nombre de registres dits "d'index" sont aussi disponibles (et incontournables). Leur utilité deviendra plus claire bientôt. En attendant, en voici une liste descriptive un peu sommaire (mais c'est de bon coeur).
Le registre SP (ou ESP sur 32 bits) sert à noter, avec SS (le segment de pile) la position en mémoire de la pile d'exécution du programme. Cet instrument fera l'objet (bientôt) d'un examen approfondi.
Le registre BP (ou EBP sur 32 bits) indique une base pour fins d'adressage indexé. On utilise habituellement ce registre avec un déplacement ("offset") pour exprimer des adresses en mémoire, surtout par rapport au début du segment de données (DS).
Par exemple, pour adresser les variables locales d'une fonction, on peut placer BP là où commence la première d'entre elles, et calculer le déplacement en fonction de la taille des données entre cette base et l'adresse de la variable à adresser.
Les registres DI et SI (EDI et ESI sur 32 bits) servent principalement à manipuler des chaînes de caractères, et aident à faire des opérations sur des suites contiguës en mémoire de données de même nature (des tableaux... que vous reverrez à la fois en 420 201 et en 420 231 au cours des prochaines semaines).
Enfin, tel que promis, il y a le pointeur d'instruction (IP), qui indique à tout moment l'adresse en mémoire de la prochaine instruction à effectuer. Sa valeur est mise à jour à chaque fois que le processeur passe à une nouvelle instruction.
L'adressage au niveau du langage d'assemblage est une considération importante. Nous avons choisi de vous offrir quelques exemples simples vous offrant un aperçu de ce qu'impliquent ces considérations, pour vous aider à saisir leur rôle.
Soyez prudent(e)s: la présente est incomplète, et elle se veut une introduction au concept, pas un document explicatif détaillé sur l'adressage en langage d'assemblage. Elle a pour but de vous aider à lire du code assembleur, y compris celui généré par VC pour vos programmes.
On peut déposer le contenu d'un registre dans un autre sans problème, dans la mesure ou les deux registres ont la même taille: on peut par exemple faire
MOV EBX,ECX ; EBX <--ECX, deux registres 32 bits |
mais on ne pourrait pas faire
MOV BX,CL ; CL est un registre 8 bits, et BX un registre 16 bits |
Supposons qu'on veuille déposer le contenu de l'octet se trouvant à l'étiquette XYZ dans le registre AL (huit bits).
Cela s'avère possible par ce qu'on appelle l'adressage direct, et la syntaxe sera:
.DATA ; segment de données XYZ "ALLO TOI!" ; les caractères A L L O ... sont à l'adresse XYZ .CODE ; segment de code MOV AL,[XYZ] ; le caractère 'A' est déposé dans AL ADD AL,3 ; AL contient le code ASCII du caractère 'D' MOV [XYZ],AL ; XYZ devient "DLLO TOI" |
Supposons qu'on veuille déposer une valeur constante dans un registre.
Cela s'avère possible par ce qu'on appelle l'adressage immédiat, et la syntaxe sera:
MOV BX,12 ; BX <-- 12 (8 bits). Ok: BX est 16 bits MOV BX,6000 ; BX <-- 6000 (16 bits). Ok: BX est 16 bits MOV BL,6000 ; BL <-- 6000 (16 bits). Incorrect: BL est 8 bits |
[1] Nous y reviendrons sous peu, mais gardons en tête qu'un programme est composé de code--d'instructions--et de données, mais que ce sont là deux choses distinctes.
[2] Par abus de langage, on pourrait aussi ajouter ce qu'on nomme le tas (en anglais: "heap"). Pour l'instant, nous mentionnerons simplement son existence.
[3] ...ce qui est presque toujours équivalent à la taille du type "int" en C et en C++. Il est préférable de ne pas compter là-dessus, mais puisqu'on prend parfois cette adéquation pour acquis en entreprise, il est préférable que vous en soyez a priori informés.
[4] À ce stade-ci, vous devriez être à l'aise avec des considérations comme extraire un octet d'un entier codé sur 32 bits, ou connaître la valeur de la partie haute d'un entier d'une certaine taille.
[5] on dira alors que l'objet est aligné sur un multiple de la taille du mot mémoire (ex: aligné sur 4 octets).
[6] Une étiquette (ou label) est une ligne de code assembleur portant un nom. On se sert d'étiquettes pour permettre les sauts et les branchements dans le code, par exemple dans le but de générer des boucles...
[7] Les registres seront présentés sous peu. Patience!
[8] ... que nous ne couvrirons pas aujourd'hui, mais n'ayez crainte: ça s'en vient!