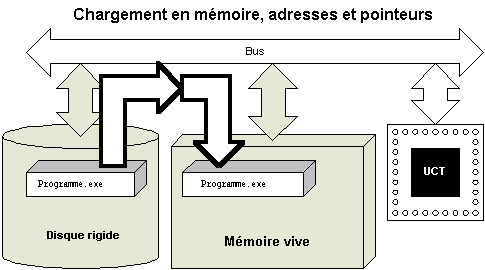
Nous allons maintenant ouvrir une parenthèse pour présenter comment s'organise, en mémoire, le code objet généré par la compilation.
Nous quitterons pour ce faire la mécanique de la génération d'un exécutable et celle de l'exécution d'un programme pour parler un peu d'adresses et de pointeurs dans les langages C et C++.
Avertissement (1)
Ce qui sera enseigné ici est utile pour le type de programmation demandé par le cours 420 231. Ne l'utilisez pas dans le cours 420 201, où jouer trop près de la machine nuirait à votre compréhension du cours. Il est préférable d'avoir un peu d'expérience derrière la cravate avant de mélanger la programmation de haut et de bas niveau, et ce ne serait pas une bonne idée pour le type de programmation faite en 2ième session.
Avertissement (2)
Ce document utilisera à l'occasion le mot objet pour parler à la fois de variable, de constante, de sous-programme... Je vous en prie, ne confondez pas le mot objet utilisé comme généralisation avec l'idée d'objet tel que vue en 420 201.
Un petit rappel est nécessaire avant d'aller plus loin, relativement aux adresses. Ce mot devient de plus en plus important au fur et à mesure que nous avançons, et nous devrons être à l'aise avec lui pour bien comprendre le sujet à l'étude.
Qu'est-ce qui, dans un programme, a une adresse? La réponse est simple: absolument tout, ce qui est en mémoire, les instructions comme les données:
Prenons un (très) petit exemple pour nous mettre à l'aise (les numéros attribués, sous forme de commentaires, à la droite de chaque ligne, nous serviront plus loin de référence):
int main ()
{ // (0)
int a= 3, b= 5, c; // (1)
c= a + b; // (2)
} // (3)
|
Confrontant ce code, le compilateur devra accomplir un certain nombre de tâches. Nous essaierons de les détailler pour clarifier le processus qui mènera à la génération de l'exécutable correspondant.
L'instruction "int main () {" débute la définition du sous-programme. Nous devrons passer outre les détails propres à ce type d'instruction pour le moment (n'ayez crainte: nous reviendrons sous peu à la charge!), mais nous observerons toutefois que l'accolade ouvrante "{" dénote le début d'un contexte.
Dans les langages C et C++, les contextes sont dénotés par les accolades ouvrantes "{" et fermantes "}".
L'idée de définir un contexte est riche, mais nous intéresse ici dans le sens qu'elle définit la durée de vie des objets qui lui appartiennent, leur portée.
En effet, un objet déclaré dans un contexte a une durée de vie déterminée par l'étendue de ce contexte. Dans notre petit programme en exemple, les variables entières "a", "b" et "c" ont une portée allant du moment de leur déclaration (1) à la fin du contexte dans lequel elles ont été déclarées (3).
Pour s'exécuter, chaque programme doit avoir un (et un seul!) point de départ. En C et en C++, ce point de départ est le sous-programme "main()", qui doit par conséquent être unique pour tout l'exécutable. Chaque exécutable C ou C++ doit avoir un (et un seul) sous-programme "main()" pour l'ensemble des fichiers ".obj" dont il est constitué.
Pour générer ce contexte, le compilateur doit (a) insérer le code requis pour débuter un programme[2], puis (b) décider d'un point bien précis dans le code qu'il est le point de départ de la fonction "main()" en question.
Il peut paraître anodin d'indiquer "adresse de la première instruction à partir du début du programme". Pourtant, cet énoncé est lourd de signification.
Mettons-nous en situation. Le compilateur génère du code objet pour un programme, et doit décider, par exemple, des tailles des différentes variables rencontrées. Ceci est possible parce que toute variable est d'un certain type, et parce que le type d'une variable en indique la taille. Mais...
| Question piège: | est-il possible de déterminer, à la compilation, l'adresse réelle de chaque variable--celle où la variable se trouvera en mémoire? Pourquoi? |
La réponse est non: en effet, pour savoir l'adresse réelle d'une variable (ou d'une constante, ou d'une fonction, ou...), il faut savoir où le programme se trouvera en mémoire une fois chargé du disque rigide. Et cela n'est pas connu du compilateur alors qu'il traverse le programme pour générer le code objet correspondant.
Le compilateur, lors de la génération du code objet, doit donc se limiter à utiliser des adresses relatives au début du programme plutôt que des adresses absolues en mémoire.
L'éditeur de liens devra se limiter, lui aussi, à des adresses relatives lors de la génération de l'exécutable, puisqu'il se trouve dans la même situation que le compilateur--il ne sait pas où sera, en bout de ligne, le programme une fois chargé en mémoire.
Il existe un programme (le "loader") qu'on ne voit à peu près jamais qui sert à charger les programmes en mémoire.
C'est lui qui trouvera un endroit en mémoire pour le programme; c'est donc lui qui, lors du chargement d'un programme en mémoire, finira le travail calculera les adresses absolues à partir de l'adresse où se trouve effectivement le programme et des adresses relatives trouvées à l'intérieur.
L'adresse absolue d'une variable V se calcule comme suit:
Adresse absolue de V <-- Début du programme + Déplacement de V |
L'instruction (ou suite d'instructions) "int a= 3, b= 5, c;" est un suite de déclarations de variables, avec initialisation automatique pour certaines d'entre elles. Nous savons que ces variables existeront jusqu'à la fin de leur contexte (3), mais que savons-nous d'autre à leur sujet?
Nous savons que tout objet a une taille. Ceci implique que tout objet occupe un espace, et dans le cas qui nous intéresse cet espace est occupé en mémoire.
Occuper un espace signifie aussi, incidemment, être quelque part, donc avoir une adresse, et être constitué de quelque chose, avoir une valeur. Le vide n'existe pas en mémoire: il y a des "zéros" et des "uns", mais pas de "riens"[3].
Trois (3) propriétés fondamentales
Et ces trois considérations (localité, espace occupé et constitution, ou encore adresse, taille et valeur) sont toutes essentielles; ça peut paraître un peu philosophique, je vous l'accorde, mais c'est aussi fort concret.
Le compilateur, en rencontrant par exemple "int a", doit s'assurer qu'en quelque part se trouvera un espace suffisant pour mettre ce qui sera, à partir du moment de cette déclaration, "a".
Pour cela, il lui faut connaître l'espace requis pour ce que sera cet objet; heureusement, C++ étant un langage typé, le compilateur sait immédiatement qu'un objet de type "int" doit occuper un espace de "sizeof(int)" octets (ici: 32 bits).
Muni de ce savoir, il est en mesure de s'assurer que les prochains 32 bits[4] soient attribués pour loger cette variable.
Toute mention de "a" dans son contexte signifiera donc une interaction avec l'espace de 32 bits en mémoire qui lui a été attribué lors de sa déclaration. L'adresse de "a" sera celle du premier des quatre octets qui la constituent.
L'affectation de la valeur "3" à cette variable implique aussi une part de mécanique. Ainsi, il faudra au compilateur déposer la valeur "3" sur 32 bits à l'endroit attribué à "a" (par exemple, à l'aide de l'instruction assembleur "MOV").
Rappel: taille des constantes numériques
Petit rappel: toute constante numérique a une taille. Par défaut, les constantes entières comme "3" sont de type "int", et occupent un espace de "sizeof(int)" octets.
Il est possible de s'assurer que "3" soit de type "long" plutôt que de type "int" (surtout sur les plates-formes où ces deux types sont de taille différente) en l'écrivant "3L" plutôt que "3".
Par défaut, les constantes réelles comme "1.25" sont de type "double", et occupent un espace de "sizeof(double)" octets.
Il est possible de s'assurer que "1.25" soit de type "float" plutôt que de type "double" en l'écrivant "1.25f" plutôt que "1.25".
Le processus de génération du code machine--les humains que nous sommes utiliseront bien sûr la notation assembleur--correspondant au code objet des instructions (0) et (1) produira probablement[5] en mémoire quelque chose ressemblant à:

Portez une attention particulière aux items suivants:
| Note: | ne confondez pas cette notation avec celle utilisée pour les paramètres passés par référence: on parle du même symbole, mais pas utilisé aux mêmes endroits. Nous reviendrons sous peu sur ce sujet--ne faites pas de folies en attendant! |
Un portrait plus honnête du résultat de cette génération serait plutôt la combinaison de:
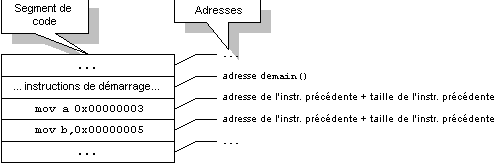
qui représente la séquence des instructions à accomplir, segment à travers lequel se "déplacera" le registre IP[6], et de:
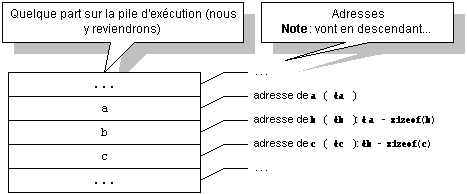
qui présente l'attribution des espaces pour les données. Il manque bien sûr des détails pour que le portrait soit complet, mais ceci devrait vous aider à vous faire une image préliminaire décente du mécanisme.
Nous l'avons vu, tout objet (en particulier, toute variable) a une adresse, et occupe un certain espace, les instructions comme le reste. Mais que trouve-t-on dans une variable si celle-ci n'a pas été initialisée?
La réponse peut varier. Certains systèmes s'assureront d'avoir des octets de valeur 0 par défaut dans tout objet servant de donnée dans un programme, d'autres n'offriront aucune garantie. En pratique, il faut absolument éviter de présumer la valeur d'une variable n'ayant pas été initialisée.
Si vous tracez votre code à l'aide du dévermineur de VC, d'ailleurs, vous verrez sans l'ombre d'un doute que le contenu des variables est à peu près aléatoire jusqu'au moment où votre code y déposera délibérément un contenu "sensé".
Pour reprendre notre exemple, le contenu de la variable "c" à la ligne (1) est indéterminé au sens de votre programme. Il s'y trouve une valeur, mais celle-ci peut changer d'une exécution à l'autre; par conséquent, votre programme ne devrait faire aucune présomption au sujet de cette valeur, sinon qu'il ne peut compter sur elle.
L'instruction (ou suite d'instructions) à la ligne (2) du code source peut s'exprimer comme suit: calculer la somme de "a" et de "b", et déposer ce résultat dans "c". Et pour nous, les mortels, ceci est suffisant.
Pour ce qui est du code machine, il y a un besoin sérieux de clarification et de développement additionnel pour en arriver à un bout de code utilisable. Raffinons--détaillons!--donc notre algorithme. Il nous faut:
Pour arriver à un résultat, nous devons donc faire preuve d'une certaine prudence. Le processeur possède, en ses registres, tout ce dont il a besoin pour traiter ces opérations, même décomposées en leur forme la plus simple.
Le compilateur fonctionnera donc probablement comme suit:
|
Problème: |
additionner deux entiers "a" et "b", et déposer le résultat de cette addition dans un autre entier "c". |
||
|---|---|---|---|
|
Question: |
quelle est la taille du plus gros des opérandes? |
Réponse: |
32 bits |
|
Opérations: |
Déposer le contenu de "a" dans un registre 32 bits, disons "EAX", par "MOV EAX,[a]", où "[a]" signifie "ce qui se trouve à l'adresse propre à l'objet de compilation a", donc les 32 bits débutant à cette adresse du fait de son dépôt dans un registre de cette taille. |
||
|
|
|||
|
|
|||
|
|
|||
Au total, donc, on peut s'attendre à quelque chose comme[7]:
MOV EAX,[a] MOV EDX,[b] ADD EAX,EDX ; résultat dans EAX MOV [c],EAX |
Tout cela peut sembler fort complexe (c'est surtout un peu long), mais au fond tout cela est plus simple que les regards de plus haut niveau auxquels nous sommes maintenant habitués. Regarder de plus près la mécanique "interne" d'un programme occulte moins le mécanisme des opérations, même les plus élémentaires.
Le contexte, tel que mentionné précédemment, se termine avec la rencontre de l'accolade fermante "}" dans le code source. Les variables déclarées dans le contexte existent du point de leur déclaration (1) jusqu'à celui, fatal, de la fin de leur contexte (3).
La gestion du contexte peut sembler relativement complexe. En effet: comment forcer le programme à ne pas reconnaître les variables automatiques, locales à une fonction, lorsqu'à l'extérieur du contexte où celles-ci sont déclarées si, au fond, les variables sont à une adresse en mémoire et si toutes les adresses sont simplement des entiers sur 32 bits?
Nous arrivons au noeud derrière la "magie" du mécanisme: grâce à ce qu'on appelle la pile d'exécution, plusieurs fois mentionnée précédemment, les variables automatiques en question n'existent même pas à l'extérieur de leur contexte.
Nous verrons, tel que promis, comment tout cela fonctionne lorsque nous attaquerons le sujet de la pile d'exécution.
En C++, il est aisé d'accéder à l'adresse d'un objet: c'est une simple question de précéder cet objet d'un "&".
Rappel important
Ne confondez pas la perluette "&" précédant une variable, dont le sens est "adresse de cette variable", avec celle précédant un paramètre dans un prototype de sous-programme, dont le sens est "ce paramètre est passé par référence".
Aussi, souvenez-vous qu'il est strictement interdit d'utiliser cette notation, pour accéder directement à une adresse, en 420 201. Considérez-vous prévenus!
Prenons par exemple le programme suivant:
#include <iostream>
using namespace std;
int main()
{
int a = 3; // a est un entier signé sur 32 bits, de valeur 3
cout << a << " " // écrit: contenu de "a", donc 3
<< &a << endl; // écrit: adresse de "a", ex: 0xa88bc
}
|
Afficher l'adresse d'une variable présentera à l'écran un gros nombre quelconque. Ce nombre est très important (puisqu'il dénote l'endroit où se trouve la variable en question), mais ne fait pas beaucoup de sens pour un usager.
Lorsqu'on manipule une adresse, qui est en fait l'endroit en mémoire d'un objet d'une certaine taille, on s'intéresse souvent à son contenu.
Si "a" est un "int", alors "&a" signifie "adresse de l'entier signé sur 32 bits a", et "*(&a)" signifie "contenu sur de l'entier signé sur 32 bits débutant à l'adresse de a".
Ainsi, "a" est équivalent à "*(&a)".
Reprenant notre exemple, le programme (omission faite des "#include" etc.):
int main()
{
int a = 3;
cout << a << " " << &a << " " << *(&a) << endl;
}
|
affichera "3 0xa88bc 3".
Jusqu'ici, l'intérêt de savoir manipuler et accéder à des adresses peut ne pas être évident. Il nous manque un peu de "jus" pour bien saisir la puissance du concept; cela sera plus apparent à l'aide d'un outil spécialisé dans la manipulation d'adresses.
Un outil bien spécial, donc, existe dans bien des langages (C et C++ en particulier) pour manipuler des adresses. Cet outil se nomme le pointeur.
Muni de pointeurs, on est en mesure d'écrire à une adresse précise en mémoire, de même que de lire le contenu d'une adresse spécifique. On peut aussi accomplir certaines manoeuvres assez spéciales.
Une nouvelle fois
Si vous utilisez des pointeurs en 420 201, votre professeur va faire une syncope justifiée, blêmir et se fâcher. Restreignez l'emploi de pointeurs et d'adresses pour les cas où ils sont nécessaires--en 420 231.
Remarquez que si un astérisque précède une variable lors de sa déclaration, cela signifie que cette variable sera un pointeur. Ainsi, dans les déclarations suivantes, "a" est un "short", "b" est un pointeur vers un "short", et "c" est un "short".
short a, *b, c; |
Ainsi, "a" et "b" ne sont pas du même type: "a" est un "short", donc un entier signé sur 16 bits, alors que "b" est un pointeur vers un "short", donc une adresse--un entier non signé sur 32 bits.
Remarquez que si un astérisque précède une variable ailleurs que lors de sa déclaration, cela signifie qu'on accède au contenu pointé par cette variables--à ce qui se trouve à l'adresse qu'elle contient. Cette variable doit alors être un pointeur, sinon l'instruction sera invalide.
L'exemple suivant illustre cette différence:
short a, *b;
*a = 5; // invalide: "a" n'est pas un pointeur
b = &a; // valide: "b" est un pointeur de "short", et
// "&a" est l'adresse d'un "short"
*b = 5; // valide: "b" est un pointeur de "short". Cette
// opération a pour effet de déponser la valeur 5
// là où pointe "b"... donc dans "a"
|
Exemple: le programme suivant utilise un mélange de variables, d'adresses et de pointeurs. Les commentaires à la droite de chaque instruction visent à décrire l'impact de chacune d'entre elles
int main ()
{
int a, // valeur de "a": indéterminée
b= 3; // valeur de "b": 3
int *p; // "p" est un pointeur vers un "int"
p= &a; // "p" <-- l'adresse de "a"; "p" pointe vers "a"
*p= 4; // le contenu pointé par "p"--donc "a"--reçoit 4
b+= a; // "b" devient égal à 7!
}
|
Les pointeurs peuvent être difficiles à visualiser à prime abord, du fait que leur contenu est en fait un lieu, une adresse, plutôt qu'une donnée conventionnelle. Pour s'y retrouver, on a souvent recours à des schémas.
Par exemple, pour le programme précédent, nous pourrions schématiser comme suit:
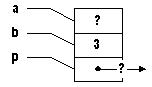
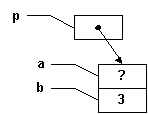
Remarquez la notation de "p", avec une flèche: cela signifie l'endroit pointé par "p". |
Initialement, les trois variables sont déclarées et sont de même taille: "a" et "b" sont tous deux des entiers signés sur 32 bits, et "p" représente l'adresse d'un entier, et par conséquent occupe aussi un espace de 32 bits. Les contenus de "a" de "p" dans ce schéma sont tous deux inconnus (d'où les "?"). |
Une fois que l'opération "p= &a" est traitée, nous obtenons le schéma suivant:
|
Bien sûr, "p" n'a pas bougé, mais le contenu de "p" est maintenant l'adresse de "a". Ainsi, "p pointe vers a", ou encore "p contient l'adresse de a". |
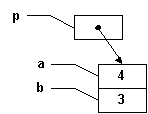
Ainsi, la ligne "*p= 4" résultera en:
|
... et ce, puisque modifier le contenu pointé par "p" est exactement la même chose que modifier "a". Il y a de réels bénéfices à utiliser des pointeurs, de même que de considérables dangers. |
Historiquement, en langage C, il n'y avait que des paramètres par valeur. Ceci signifie que la seule manière pour une fonction de communiquer avec la fonction l'ayant appelé était par sa valeur de retour, ou par des variables globales.
| Note: | l'avènement en C++ du passage de paramètres par référence a résolu ce problème philosophique en C++, et c'est pourquoi les pointeurs, quoique toujours importants, sont moins essentiels qu'ils ne l'étaient auparavant. |
En langage C, par l'utilisation de pointeurs, une fonction pouvait contourner ce problème et affecter (en quelque sorte) ses paramètres.
Le cours 420 231 se doit d'aborder la question des pointeurs, même si ce n'est qu'en surface, parce que la plupart des outils permettant de programmer près du matériel de l'ordinateur utilisent cette façon de faire. Mais en général, s'il est possible d'éviter de jouer avec des pointeurs, on en profite et on s'en tient à du code moins délicat.
Souvenons-nous de notre premier cours de programmation (420 101). En langage C++, les paramètres des sous-programmes sont normalement passés par valeur; lorsque nous avons voulu écrire une procédure "Echanger()" qui échangeait les valeurs de deux entiers, il nous a fallu utiliser des paramètres passés par référence.
En langage C, l'ancêtre du C++, il n'y avait pas de références. Pour écrire la fonction "Echanger()", il fallait absolument utiliser des pointeurs. Ça fonctionne, mais c'est beaucoup plus lourd sur le plan syntaxique.
À titre d'illustration, l'exemple suivant présente deux versions de la fonction "Echanger()" et d'un programme l'appelant. Celle de gauche utilise des pointeurs, et celle de droite des références. Cela devrait montrer pourquoi on préfère utiliser des références autant que possible.
|
Avec pointeurs |
Avec références |
|---|---|
void Echanger (int *x, int *y)
{
int Temp;
Temp = *x;
*x = *y;
*y = Temp;
}
int main ()
{
int a = 3,
b = 5;
Echanger (&a, &b);
}
|
void Echanger (int &x, int &y)
{
int Temp;
Temp = x;
x = y;
y = Temp;
}
int main ()
{
int a = 3,
b = 5;
Echanger (a, b);
}
|
Remarquez les endroits en caractères gras:
Pourquoi l'exemple utilisant des pointeurs comme paramètres permet-il à la procédure "Echanger()" d'accomplir correctement sa tâche?
|
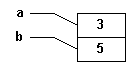
Dans le programme principal, il existe deux variables "a" et "b", toutes deux de type "int". Bien entendu, chacune a une adresse. L'adresse de "a" s'écrit "&a" et celle de "b" s'écrit "&b". |
|
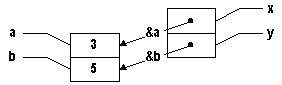
Lors de l'appel de la procédure "Echanger()", on passe en paramètre "&a" et "&b".
Notez la position des "&": ailleurs qu'à la déclaration d'une variable ou d'un paramètre, ce symbole représente l'adresse de la variable, pas une référence.
|
Cela signifie que les paramètres "x" et "y", qui sont tous deux de type "int*", prendront respectivement comme valeur une copie de l'adresse de "a" et une copie de l'adresse de "b". |
Le truc ici est que bien que "x" soit une copie de l'adresse de "a" et "y" une copie de celle de "b", modifier le contenu pointé par "x" modifie quand même "a" et modifier "y" altère quand même "b".
Cela dit: quand vous avez accès aux références, tenez-vous en aux références, et évitez les pointeurs. Plus simple, plus propre, moins risqué.
Soit le petit programme suivant:
typedef struct
{
int x, y;
}
Point;
int main ()
{
Point p1, *p2;
p2 = &p1;
}
|
Accéder à un membre de "p1" se fait à travers l'opérateur ".". Par exemple, "p1.x= 3;" et "p1.y= p1.x+ 10;" sont deux opérations valides.
Accéder à un membre du "Point" pointé par "p2" peut se faire de deux façons:
Voici un exemple d'utilisation de pointeurs avec une fonction initialisant une structure:
#include <iostream>
using namespace std;
// un Point décrit un point par ses coordonnées x et y
typedef struct
{
int x, y;
} Point;
// Initialiser_Point () prend l'adresse d'un Point et affecte
// aux membres x et y du Point pointé de nouvelles valeurs...
void Initialiser_Point (Point *p, int Nouv_X, int Nouv_Y)
{
*p.x = Nouv_X; // équivalent: p->x = Nouv_X;
*p.y = Nouv_Y; // équivalent: p->y = Nouv_Y;
}
int main ()
{
Point Un_Point;
InitialiserPoint (&Un_Point, 3, 4);
// L'opération suivante affichera "(3,4)"
cout << "("
<< Un_Point.x
<< ","
<< Un_Point.y
<< ")"
<< endl;
}
|
Bien entendu, avec des paramètres par référence en C++, on pourrait plus simplement faire ce qui suit (seules les lignes pertinentes apparaissent ci-après):
// Initialiser_Point () prend une référence à un Point et affecte
// aux membres x et y de ce Point de nouvelles valeurs...
void Initialiser_Point (Point &p, int Nouv_X, int Nouv_Y)
{
p.x = Nouv_X;
p.y = Nouv_Y;
}
int main ()
{
Point Un_Point;
InitialiserPoint (Un_Point, 3, 4);
// L'opération suivante affichera "(3,4)"
cout << "("
<< Un_Point.x
<< ","
<< Un_Point.y
<< ")"
<< endl;
}
|
Prises une à une, les instructions des deux bouts de code se ressemblent beaucoup. On remarque toutefois que la syntaxe du passage de paramètres par référence est plus transparente: le passage de paramètre par adresse (par pointeur) demande qu'on manipule un objet intermédiaire (l'adresse du paramètre) plutôt que l'objet lui-même.
Le passage d'un pointeur en paramètre demeure un passage de paramètre par valeur; toutefois, puisque la valeur passée est celle d'une adresse, modifier le contenu de cette adresse permet de modifier effectivement l'objet pointé.
Le passage de paramètre par référence est un "tour de magie" du compilateur: en fait, le compilateur passe un pointeur à l'objet référé, tout en nous dissimulant cette manoeuvre. C'est de par ce pointeur caché que notre code parvient à modifier l'objet référé plutôt qu'une simple copie de celui-ci.
Y a-t-il vraiment des dangers à l'utilisation de pointeurs? Oh que si! Si on est en mesure d'écrire là où bon nous semble en mémoire, on est en mesure de modifier à peu près le contenu de tout espace en mémoire, que ce soit volontaire ou non:
Voici un exemple de manoeuvre opérationnelle[8]:
int *p; // (0) char c[4]; // (1) p= (int*) &(c[0]); // (2) *p= 0; // (3) |
À la ligne (0), on déclare "p" qui est un pointeur à un "int", donc qui devrait contenir l'adresse d'un entier sur 32 bits, et on déclare à la ligne (1) quatre entiers sur huit bits contigus en mémoire, de "c[0]" à "c[3]".
|
En mémoire, on aura donc un schéma comme celui à droite: on trouve en mémoire le "int *p" et les quatre "char" en question. Remarquez qu'ils sont tous consécutifs en mémoire, dans l'ordre de leur déclaration. On ne connaît présentement la valeur d'aucune de ces variables (d'où les "?") |
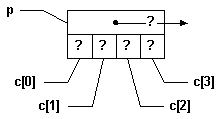
|
|
À la ligne (2), "p" reçoit l'adresse de "c[0]". La conversion explicite de type "(int*)" est pour imposer au compilateur d'accepter que l'adresse de "c[0]", qui est un "char" (entier sur huit bits) soit assignée à "p", qui est un "int*". Sur le schéma à droite, "p" et "c[0]" sont encore consécutifs en mémoire, et "p" pointe sur "c[0]". |
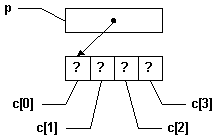
|
Pourquoi donc? À cause du danger bien réel suivant: puisque "p" pense pointer vers un entier sur 32 bits, modifier le contenu de "p" signifie modifier les 32 bits débutant à l'adresse pointée par "p".
|
Ainsi, la ligne (3) aura l'impact suivant: assigner la valeur "0x00000000" (donc "0" sur 32 bits) à l'adresse pointée par "p", ce qui est ici équivalent à "c[0]= 0x00", "c[1]= 0x00", "c[2]= 0x00" et "c[3]= 0x00", d'un seul coup. Ici, le code ne devrait pas planter à l'exécution parce qu'il advient (heureusement!) que les 32 bits débutant à "&(c[0])" sont les entiers "c[0]...c[3]"[9]. |
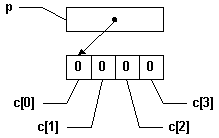
|
Agir ainsi est une très mauvaise pratique de programmation, et il vous est défendu de faire ce genre de tours de passe-passe dans vos travaux, de même que professionnellement, surtout si vous désirez garder votre emploi!
Le danger peut s'exemplifier comme suit: si nous avions par exemple écrit, à la ligne (2), ce qui suit:
p= &(c[1]); |

|
Alors le schéma se serait transformé en ce que vous voyez à gauche. Et alors, la ligne (3) enverra toujours "0" sur 32 bits débutant à &(c[1])... mais les derniers huit bits de cette séquence, à quoi servent-ils? Mystère! Et c'est là que se trouve le danger: la ligne (3) écrira "0x00" à un endroit qui peut servir à représenter à peu près n'importe quoi. |
Le risque de planter sérieusement ici est très réel! Lorsqu'on se permet pareilles imprudences, n'importe quoi (vraiment n'importe quoi!) peut flancher sans préavis.
Si vous risquez peu de commettre un impair comme celui présenté plus haut, la discussion sur les tableaux (qui suit sous peu) contient, elle, des exemples qui vous feront saisir toute la... réalité du sujet.
Un autre exemple de problème que vous pouvez rencontrer est relatif à l'ordre des octets dans un mot mémoire de la machine.
Par exemple, prenons le code suivant:
#include <iostream>
using namespace std;
int main ()
{
char T1[4]= { 0x01, 0x02, 0x03, 0x04 };
short s1;
int i1;
char* p;
// copier deux octets de "T1" dans "s1"
p= (char*) &s1; // mérite un commentaire!
*p= T1[0];
*(p+1)= T1[1];
cout << hex << s1 << dec
<< endl; // (0)
// copier quatre octets de "T1" dans "i1"
p= (char*) &i1; // mérite un commentaire!
*p= T1[0];
*(p+1)= T1[1];
*(p+2)= T1[2];
*(p+3)= T1[3];
cout << hex << i1 << dec
<< endl; // (1)
}
|
La ligne (0) affichera à l'écran "201" (pour "0x0201") plutôt que "102" (pour "0x0102"), à cause de considérations propres à la représentation interne sur la machine que nous utilisons: l'ordre des octets dans un mot n'est pas nécessairement ce qu'il semble à première vue!
De même, la ligne (1) affichera "4030201", pas "1020304". Essayez-le!
C'est pourquoi il faut être extrêmement prudent lorsqu'on effectue pareille manoeuvre: la représentation interne des nombres pour un ordinateur peut changer d'un processeur à un autre, et si nous essayons de jouer "plus bas" de notre propre chef, nous devons agir avec circonspection et vérifier nos programmes pour s'assurer que nous n'avons pas commis de faute!
Un tableau, vous l'avez vu en 420 201, représente une suite d'objets de même type disposés de façon consécutive en mémoire. Débutons notre discussion par un petit rappel.
Prenons la déclaration suivante:
int T[20]; |
On y déclare 20 objets de type "int" consécutifs en mémoire, le premier débutant là où se trouve effectivement "T[]". On accède au premier de ces 20 objets par "T[0]", au second par "T[1]", et ainsi de suite jusqu'à "T[19]".
On peut donc choisir de calculer la somme de tous les éléments de "T" par une boucle semblable à la suivante:
const int MAX_T= 20;
int T[MAX_T],
somme= 0,
iCompteur;
for (iCompteur= 0; iCompteur < MAX_T; iCompteur++)
{
somme+= T[iCompteur];
} // à la fin, "somme" contiendra la somme de "T[0]" à "T[MAX_T]"
|
Vous découvrirez sans doute mille et une façons d'appliquer cet outil à vos tâches de tous les jours. Dans le cours 420 231, nous allons jeter un regard sur ce que signifie et représente un tableau à l'interne.
Le type de chaque entrée d'un tableau comme "T[]", plus haut, est celui déclaré pour le tableau en entier. En l'occurrence pour un tableau déclaré comme "int T[MAX_T];", le type de "T[0]" est "int", tout comme l'est le type de "T[1]", celui de "T[2]", etc.
Mais qu'en est-il du type de "T[]" lui-même? On connaît le type de chaque entrée du tableau, mais quel est le type du tableau?
Concrètement, donc, un tableau comme "T[]" se représente en mémoire comme suit:

|
Si "T" est un tableau de "short", donc d'entiers sur 16 bits: Est-ce utile de connaître cet état de fait? En théorie, on devrait faire semblant qu'on n'en sait rien, mais dans les faits, ce savoir sert beaucoup, particulièrement en entreprise. Avec ce savoir, il devient possible par exemple d'écrire une fonction qui calcule la somme des éléments d'un tableau, comme celle qui suit: |
long CalculerSommeTableau (int* iTableau, unsigned int iTaille)
{
unsigned int iCompteur;
long lSomme= 0;
for (iCompteur= 0; iCompteur < iTaille; iCompteur++)
{
lSomme+= iTableau[iCompteur];
}
return (lSomme);
}
|
Ainsi, en offrant un pointeur à un entier, dans les faits un tableau d'entiers, soit un pointeur à son premier élément, et une taille, soit le nombre d'éléments du tableau, il est donc possible d'écrire une fonction qui calcule la somme des éléments d'un tableau d'entiers de taille arbitraire.
Il est essentiel de passer la taille du tableau en paramètre, pour éviter des accidents: il n'y a rien dans le tableau qui en dise la taille réelle.
Ainsi, si le code ne s'assure pas que la fonction connaisse la taille réelle allouée au tableau, par exemple avec un paramètre la spécifiant, la fonction en tant que telle pourrait très bien passer tout droit et calculer dans sa somme le contenu des "entrées" se trouvant à la suite du tableau dans la mémoire.
Une forme équivalente en tout point de cette fonction serait:
long CalculerSommeTableau (int* iTableau, unsigned int iTaille)
{
unsigned int iCompteur;
long lSomme= 0;
for (iCompteur= 0; iCompteur < iTaille; iCompteur++)
{
lSomme+= *iTableau;
iTableau++; // (*)
}
return (lSomme);
}
|
Notez que l'opérateur "++" à la ligne (*) passe au prochain "int" en mémoire, parce que "iTableau" est de type "int*"... l'arithmétique sur les pointeurs est un peu spéciale en ce sens qu'elle tient compte de la taille des objets pointés!
Remarquez que plutôt que de traiter "iTableau" comme un tableau d'entiers, nous le traitons comme un pointeur d'entier, et nous passons à chaque itération (chaque "tour de boucle") au prochain élément du tableau en ajoutant la taille d'un entier à cette adresse qu'est "iTableau".
Cette implantation de la fonction compte sur le caractère consécutif en mémoire des entrées d'un tableau. Sans cette propriété, notre fonction s'écroule comme un château de cartes au vent, et produit des résultats fort suspects.
L'arithmétique sur les pointeurs est permise en C et en C++ (alors qu'elle est interdite dans la plupart des langages de programmation dits "de haut niveau") du fait que le programmeur est supposé savoir, dans ces langages, qu'une adresse est en fait un entier codé sur un mot mémoire.
Dans la mesure du possible, pour plusieurs raisons, on cherche à oublier cet état de fait, comme on cherche à oublier toutes considérations de représentations internes... mais vous ne pouvez quand même pas partir avec un diplôme en informatique (surtout pas réussir ce cours!) sans en être conscients vous-mêmes.
On peut initialiser un tableau à sa déclaration, de la manière suivante:
const int TAILLE_T= 3;
int main ()
{
int UnTableau[TAILLE_T]= {
4, 7, -23
};
}
|
Le tableau "UnTableau[]" ici présenté aura donc les valeurs 4, 7 et -23 aux entrées 0, 1 et 2 respectivement (donc "UnTableau[1]==7", pour ne prendre qu'un exemple parmi tant d'autres).
Remarquez que ce tableau peut contenir au plus "TAILLE_T" éléments, et que le tableau est initialisé avec précisément "TAILLE_T" valeurs. En fait, on aurait pu en toute légalité utiliser moins de valeurs à l'initialisation (initialiser seulement une partie des entrées du tableau), mais on n'aurait pas été en droit d'en utiliser plus (car cela aurait causé un débordement du tableau... très vilain!).
|
Exemple 1 |
Exemple 2 |
|---|---|
const int TAILLE_T= 3;
int main ()
{
int UnTableau[TAILLE_T]= {
4, 7
};
}
|
const int TAILLE_T= 3;
int main ()
{
int UnTableau[TAILLE_T]= {
4, 7, -23, 12
};
}
|
|
On utilise seulement deux (2) valeurs pour initialiser un tableau à trois (3) entrées. Les entrées effectivement initialisées sont l'entrée 0 et l'entrée 1: les valeurs initiales d'un tableau sont attribuées selon l'ordre dans lequel ses entrées apparaissent en mémoire. |
On essaie d'utiliser quatre (4) valeurs pour initialiser un tableau à trois (3) entrées. Le compilateur refusera de générer le code pour ce programme, qu'il peut reconnaître comme visiblement erroné. |
L'appel de la fonction "CalculerSommeTableau()", plus haut, pourrait donc se faire comme suit:
const int TAILLE_TABLEAU= 7;
int main ()
{
int MonTableau[TAILLE_TABLEAU]= {
-8, 15, 3, 244, 78571, 0, -1
};
long lSommeEntrees;
// code qui modifie les entrées du tableau MonTableau[]
lSommeEntrees= CalculerSommeTableau (MonTableau,
TAILLE_TABLEAU);
cout << lSommeEntrees<< endl; // imprimera "78824"
}
|
Ce programme fonctionne parfaitement car (a) le tableau d'entiers "MonTableau" est de type "int*"; (b) le tableau en question est correctement initialisé; et (c) la taille "TAILLE_TABLEAU" passée en paramètre à la fonction est correcte.
[1] Bien que le code assembleur généré par VC utilise "word" pour dénoter un espace de 16 bits et "dword" pour un autre de 32 bits, le processeur Pentium utilise des registres 32 bits, et emploie bel et bien des mots mémoire de 32 bits.
[2] ... ce qui est un peu lourd à expliquer et tend à être particulier à chaque machine.
[3] C'est pourquoi il est fort important d'initialiser vos variables, mes snorros!
[4] ... là où il en est dans la génération du code objet lorsqu'il rencontre la déclaration de la variable.
[5] Le code exact généré dépendra du compilateur, et des options utilisées lors de la compilation. Nous nous limiterons à un modèle simplifié, pour fins pédagogiques, car il s'agit là d'un domaine très vaste, où la compétition entre les compagnies est féroce.
[6] ... qui contient, rappelons-le, l'adresse de la prochaine instruction à traiter.
[7] Prudence: le code assembleur change d'une plate-forme à l'autre, d'un compilateur à l'autre, et il faut donc se montrer tolérant si le professeur ne donne pas à 100% le même résultat que le compilateur VC dernier cri... quoique les deux doivent être relativement près l'un de l'autre dans ce cas.
[8] ... mais à éviter. Les exemples sont là pour démontrer le concept, pas pour vous inciter à mal travailler.
[9] ... que nous y avons judicieusement placées, vlimeux que nous sommes.